Project Overview
This project addresses the challenge of automatically categorizing high-volume customer support queries in the banking sector. Using the Banking77 dataset, which contains over 13,000 queries across 77 unique intent categories, we implemented and compared two distinct approaches to text classification.
Business Problem
Manually triaging thousands of customer queries is slow, expensive, and prone to human error. An accurate intent classification system allows for instant routing to the correct department, automated self-service responses, and improved customer satisfaction scores.
Project Goals
- Develop a baseline classification model using traditional machine learning techniques.
- Implement a state-of-the-art transformer-based model using Parameter-Efficient Fine-Tuning (PEFT).
- Compare performance trade-offs between speed, complexity, and accuracy.
- Demonstrate the efficacy of Low-Rank Adaptation (LoRA) for natural language tasks.
Dataset Overview
The Banking77 dataset is a fine-grained intent detection dataset specifically for the banking domain. It contains 13,083 customer service queries labeled with one of 77 intents, such as "activate_card", "balance_not_updated_after_bank_transfer", or "wrong_amount_of_cash_received".
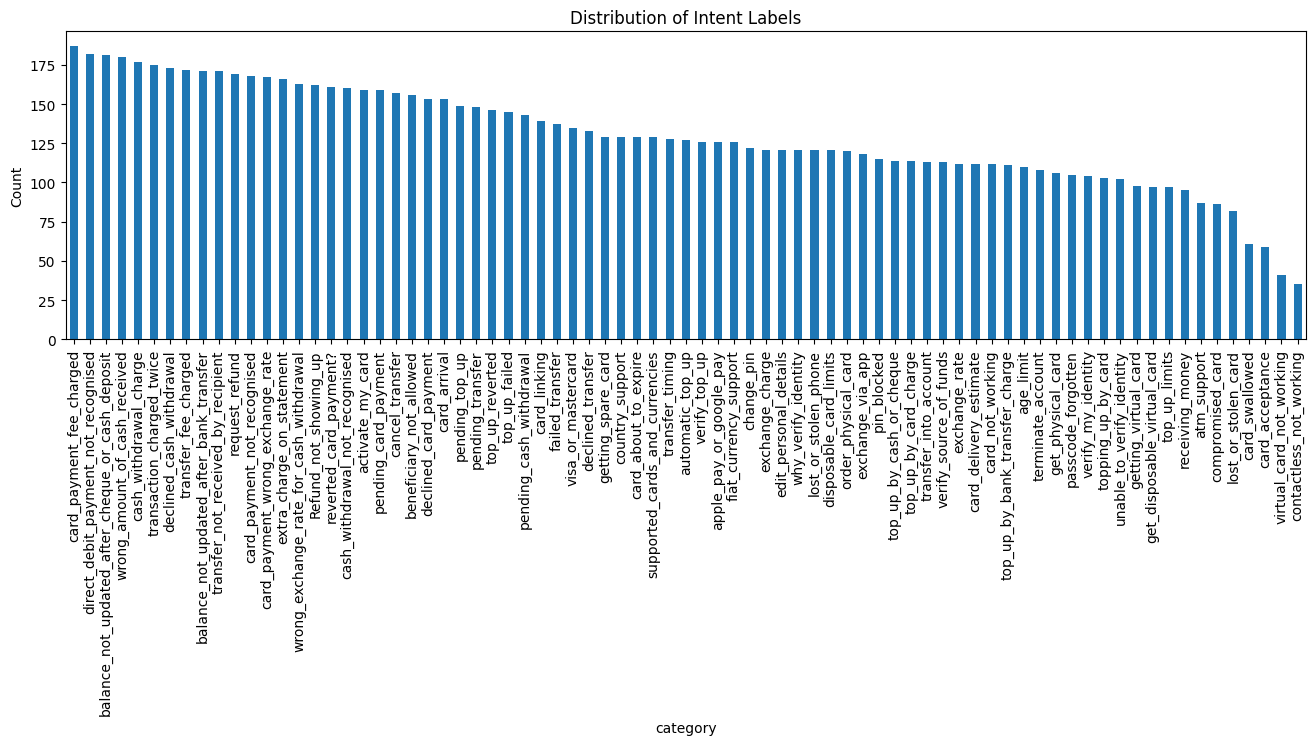
Figure 1: Distribution of intent labels in the Banking77 dataset, showing the frequency of queries across all 77 categories.
Methodology
We adopted a comparative research design to evaluate the performance gain provided by modern LLM fine-tuning techniques over traditional architectures.
Data Preprocessing
For the baseline model, we used TF-IDF (Term Frequency-Inverse Document Frequency) vectorization to transform text into numerical features. For the RoBERTa model, we utilized the RoBERTa tokenizer to convert raw text into input IDs and attention masks compatible with the transformer architecture.
Model Architectures
Baseline: Multi-Layer Perceptron (MLP)
- Input: TF-IDF vectors.
- Architecture: Fully connected dense layers with ReLU activation.
- Training: Fast, CPU-efficient, but lacks semantic understanding of word order.
Advanced: RoBERTa + LoRA
- Foundation Model:
roberta-basefrom Hugging Face. - PEFT Technique: Low-Rank Adaptation (LoRA) was applied to the query and value projections in the attention layers.
- Efficiency: Reduced the number of trainable parameters to less than 1% of the total model size, enabling faster training and lower memory usage while maintaining performance.
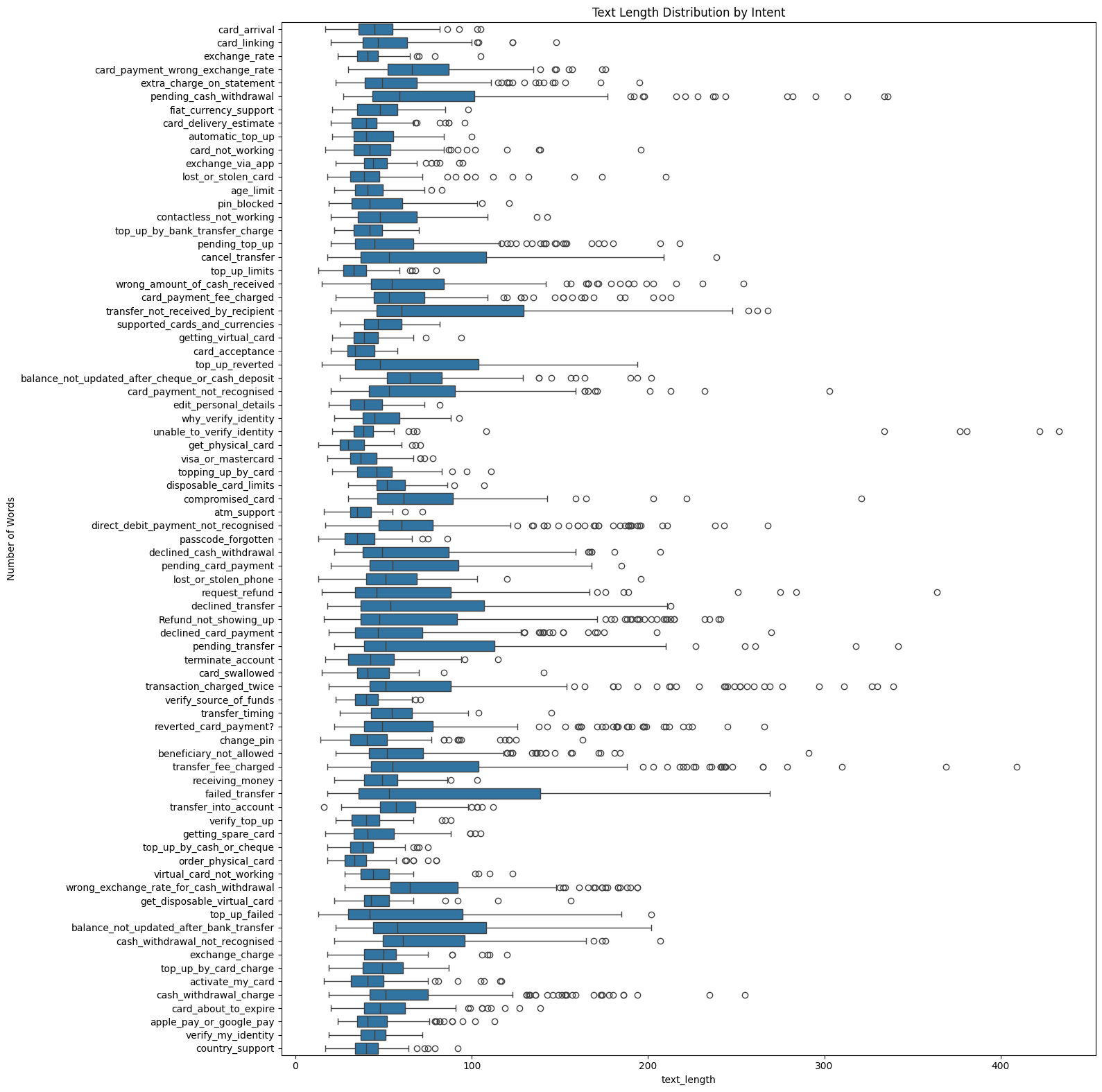
Figure 2: Text length distribution by intent category, highlighting the variability in customer query lengths across different intents.
Results
The comparison revealed a significant performance gap between the traditional MLP approach and the fine-tuned RoBERTa model.
Key Findings
- Accuracy: RoBERTa-LoRA significantly outperformed the MLP baseline, achieving 93.67% accuracy compared to 87.79% for the baseline.
- Macro F1: The transformer model reached 93.67% Macro F1, a 5.85% improvement over the MLP's 87.82%.
- Semantic Nuance: The model excelled in complex categories like
contactless_not_working(96.10% F1 vs 72.72% for MLP).

Figure 3: Word clouds showing the most frequent terms across key banking intent categories, illustrating the semantic themes the models must distinguish.
Recommendations
Based on the findings of this project, we provide the following recommendations for implementing automated intent classification in a production environment.
Model Selection
For production banking applications where accuracy is critical, RoBERTa-LoRA should be favored over simpler MLP architectures. The semantic understanding provided by transformers is essential for handling the complexity of financial queries.
Implementation Strategy
- Utilize PEFT: Implement LoRA or similar techniques to keep infrastructure costs low and deployment speeds high.
- Continuous Learning: Regularly update the model with new, anonymized customer queries to adapt to changing banking trends and terminology.
- Human-in-the-Loop: Route low-confidence predictions to human agents to ensure quality and provide training data for future model versions.
Jupyter Notebook
The complete implementation, including data loading, model training, and performance evaluation, is available in the embedded notebook below. This workflow demonstrates the practical use of the Hugging Face ecosystem for advanced NLP tasks.
Loading notebook... This may take a moment.